- 1. რა არის SQL ?
-
SQL ანუ Structured Query Language - სტრუქტურიზებული მოთხოვნების ენა,
რომლის დახმარებითაც შესაძლებელია მონაცემთა ბაზებთან წვდომა და იქ შენახული
ინფორმაციით მანიპულირება. SQL არის ANSI-სტანდარტი (American National
Standards Institute).
რა შეუძლია SQL-ს ?
- მოთხოვნების გაკეთება მბ-ში
- ინფორმაციის ამოღება მბ-დან
- ინფორმაციის დამატება მბ-ში
- მონაცემთა განახლება მბ-ში
- მონაცემთა წაშლა მბ-ში
- ახალი მბ-ს შექმნა
- ახალი ცხრილების შექმნა მბ-ში
SQL და ვებ-გვერდი
იმისათვის რომ ვებ-გვერდზე გამოვიტანოთ მბ-დან წამოღებული ინფორმაცია საჭიროა :- RDBMS პროგრამა (relational database management system) ანუ რელაციური ბაზების მართვის სისტემა (მაგ: MS Access, SQL Server, MySQL). RDBMS-ში ინფორმაცია შენახულია მბ-ს ობიექტებში ანუ ცხრილებში, ცხრილი მოიცავს ერთმანეთთან დაკავშირებულ ინფორმაციათა ნაკრებს და შედგება სვეტებისა და სტრიქონებისაგან.
- სერვერულ მხარეზე სამუშაო რომელიმე ენა, მაგ: PHP ან ASP.
- უშუალოდ SQL, მბ-დან ინფორმაციის წამოსაღებად.
- HTML / CSS - ით გამართული საიტი.
SELECT * FROM Customers;ყველაზე მნიშვნელოვანი SQL განაცხადებია :- SELECT - მბ-დან ინფორმაციის ამოღება.
- UPDATE - მბ-ში ინფორმაციის განახლება.
- DELETE - მბ-ში ინფორმაციის წაშლა.
- INSERT INTO - მბ-ში ინფორმაციის ჩასმა.
- CREATE DATABASE - ახალი მბ-ს შექმნა
- ALTER DATABASE - მბ-ს განახლება.
- CREATE TABLE - ცხრილის შექმნა მბ-ში.
- ALTER TABLE - ცხრილის განახლება.
- DROP TABLE - ცხრილის წაშლა.
- CREATE INDEX -ინდექსის შექმნა (საძიებო გასაღები.)
- DROP INDEX - ინდექსის წაშლა.
-
DDL - Data Definition Language ანუ მონაცემთა განსაზღვრის ენა
- CREATE - კონკრეტული ობიექტების შექმნა ბაზში
- ALTER - ბაზის სტრუქტურის შეცვლა
- DROP - კონკრეტული ობიექტების წაშლა ბაზიდან
- TRUNCATE - ცხრილიდან ყველა ჩანაწერის წაშლა, (გამოვიყენე ცხრილის დარესეტების დროს)
- COMMENT - კომენტარის დამატება მონაცემთა ლექსიკონში
- RENAME - კონკრეტული ობიექტებისათვის სახელის შეცვლა
-
DML - Data Manipulation Language ანუ მონაცემებით მანიპულირების ენა
- SELECT - ინფორმაციის ამოღება ბაზიდან
- INSERT - ინფორმაციის ჩასმა ბაზაში
- UPDATE - ინფორმაციის განახლება ცხრილში
- DELETE - კონკრეტული ჩანაწერის წაშლა
- MERGE - UPSERT ოპერაცია (ჩასმა ან განახლება)
-
DCL - Data Control Language მომხმარებელთა უფლებების კონტროლის ენა
- GRANT - მომხმარებელს აძლევს პრივილეგიებით სარგებლობის უფლებას
- REVOKE - GRANT - ით მინიჭებული პრივილეგიების ცვლილება
- 2. SELECT განაცხადი
-
SELECT განაცხადი
SELECT განაცხადი გამოიყენება მბ-დან მონაცემთა ამოსაღებად, დაბრუნებულ პასუხს პირობითად ვუწოდოთ შედეგთა სიმრავლე.SELECT column1, column2, ... FROM table_name;column1, column2, ... არის იმ ველების სახელები რომელთა მნიშვნელობების ამოღებაც გვინდა ჩანაწერებიდან, ხოლო თუ ყველა ველი გვაინტერესებს, მაშინ ბრძანების სინტაქსი ასეთია :SELECT * FROM table_name;საჩვენებელი მონაცემთა ბაზის ცხრილი იყოს რაიმე ამდაგვარი :
ამოვარჩიოთ მხოლოდ CustomerName და City ველები ამ ცხრილიდან :CustomerID CustomerName ContactName Address City PostalCode Country 1 Alfreds Futterkiste Maria Anders Obere Str. 57 Berlin 12209 Germany 2 Ana Trujillo Emparedados y helados Ana Trujillo Avda. de la Constitución 2222 México D.F. 05021 Mexico 3 Antonio Moreno Taquería Antonio Moreno Mataderos 2312 México D.F. 05023 Mexico 4 Around the Horn Thomas Hardy 120 Hanover Sq. London WA1 1DP UK 5 Berglunds snabbköp Christina Berglund Berguvsvägen 8 Luleå S-958 22 Sweden SELECT CustomerName, City FROM Customers;SELECT DISTINCT განაცხადი
ინგლ: Distinct - 1) აშკარა , მკვეთრი 2) განსხვავებული;
SELECT DISTINCT განაცხადი გამოიყენება მხოლოდ განსხვავებული მნიშვნელობების მქონე ჩანაწერების დასაბრუნებლად, სინტაქსი ასეთიაSELECT DISTINCT column1, column2, ... FROM table_name;Country სვეტის მნიშვნელობა მოყვანილი ცხრილის რამოდენიმე ჩანაწერში მეორდება (Mexico). მაგალითად გვინდა გავიგოთ თუ რამდენი სხვადასხვა ქვეყნიდან გვყავს დარეგისტრირებული მომხმარებლები ამისათვის განმეორებადი მნიშვნელობები არ გამოგვადგება და ამიტომ უნდა მოვიქცეთ ასე :SELECT DISTINCT Country FROM Customers;ამ ჩანაწერით განსხვავებულ ქვეყნებიანი ჩანაწერები კი ამოირჩევა მაგრამ მათ რაოდენობას გავიგებთ თუ ასეთ ჩანაწერს გავაკეთებთ :SELECT COUNT(DISTINCT Country) FROM Customers; - 3. WHERE წინადადება
-
WHERE წინადადება გამოიყენება ჩანაწერთა გასაფილტრად, მისი მეშვეობით პასუხად
ვღებულობთ მხოლოდ იმ ჩანაწერებს, რომლებიც აკმაყოფილებემ მითითებულ
პირობას.
SELECT column1, column2, ... FROM table_name WHERE პირობა;WHERE წინადადება გამოიყენება არა მარტო SELECT განაცხადში.
ჩვენი ცხრილიდან ამოვარჩიოთ (ცხრილი მოყვანილია მე-2-ე თავში) ის მომხმარებლები რომლებიც არიან მექსიკიდან :SELECT * FROM Customers WHERE Country='Mexico';შენიშნვა: SQL ითხოვს, რომ ტექსტური მნიშვნელობები აუცილებლად ჩაისვას ბრჭყალებში, რიცხვითი მნიშვნელობებისათვის კი ეს აუცილებელი არაა.SELECT * FROM Customers WHERE CustomerID=1;WHERE წინადადების ოპერატორები
WHERE წინადადებაში შეიძლება გამოვიყენოთ შემდეგი ოპერატორებიოპერატორი აღწერა = უდრის <> არ უდრის. შენიშნვა: SQL-ის ზოგიერთ ვერსიაში ეს ოპერატორი შეიძლება ჩაიწეროს ასე: != > მეტია < ნაკლებია >= მეტია ან ტოლი <= ნაკლებია ან ტოლი BETWEEN მოთავსებულია მითითებულ დიაპაზონში LIKE ნიმუშის ძებნა IN რამოდენიმე შესაძლო მნიშვნელობის მითითება - 4. AND, OR და NOT ოპერატორები
-
WHERE წინადადებაში შესაძლებელია AND, OR და NOT ოპერატორების ჩართვა. AND და OR ოპერატორები გამოიყენება ჩანაწერების გასაფილტრად ერთი არ ნამდენიმე
პირობით. AND ოპერატორი ამოარჩევს ჩანაწერს თუ ამ ოპერატორით ერთმანეთისაგან გამოყოფილი ყველა პირობა ჭეშმარიტია, OR ოპერატორი კი აარჩევს
ჩანაწერს თუ ამ ოპერატორით ერთმანეთისაგან გამოყოფილი პირობებიდან რომელიმე ჭეშმარიტია. NOT ოპერატორი კი აარჩევს ჩანაწერს თუ პირობა
(პირობები) მცდარია.
AND ოპერატორი
სინტაქსი ასეთიაSELECT column1, column2, ... FROM table_name WHERE condition1 AND condition2 AND condition3 ...;კონკრეტული მაგალითი კი ასეთიSELECT * FROM Customers WHERE Country='Germany' AND City='Berlin';OR ოპერატორი
სინტაქსი ასეთიაSELECT column1, column2, ... FROM table_name WHERE condition1 OR condition2 OR condition3 ...;კონკრეტული მაგალითი კი ასეთიSELECT * FROM Customers WHERE City='Berlin' OR City='München';NOT ოპერატორი
სინტაქსი ასეთიაSELECT column1, column2, ... FROM table_name WHERE NOT condition;კონკრეტული მაგალითი კი ასეთიSELECT * FROM Customers WHERE NOT Country='Germany';AND, OR და NOT ოპერატორების კომბინაცია
SELECT * FROM Customers WHERE Country='Germany' AND (City='Berlin' OR City='München');SELECT * FROM Customers WHERE NOT Country='Germany' AND NOT Country='USA'; - 5. სიტყვა გასაღები ORDER BY
-
სიტყვა გასაღები ORDER BY გამოიყენება შედეგთა ნაკრების ზრდადობით ან კლებადობით დასალაგებლად, ნაგულისხმეობის პრინციპით ეს გასაღები ჩანაწერებს ა
ბრუნებს ზრდადობის მიხედვით ხოლო თუ კლებადობის მიხედვით დალაგება გვინდა უნდა მივაშველოთ კიდევ ერთი სიტყვა გასაღები DESC (ინგლ: Descending -
დამავალი).
SELECT column1, column2, ... FROM table_name ORDER BY column1, column2, ... ASC|DESC;SELECT * FROM Customers ORDER BY Country;SELECT * FROM Customers ORDER BY Country DESC; - 6. INSERT INTO განაცხადი
-
INSERT INTO განაცხადი გამოიყენება მბ-ს ცხრილში ახალი ჩანაწერის ჩასამატებლად. INSERT INTO განაცხადის ჩაწერა შესაძლებელია ორნაირად: პირველი გზა ისსაა
რომ ჩანაწერში გამოვიყენოთ კონკრეტული ველების დასახელებები და მათი კონკრეტული მნიშვნელობები
INSERT INTO table_name (column1, column2, column3, ...) VALUES (value1, value2, value3, ...);მეორე შემთხვევაში კი თუ ცხრილის ყველა სვეტის მნიშვნელობები შეგვაქვს ჩანაწერში მაშინ SQL მიმართვაში სვეტების სახელების მითითება არ არის აუცილებელი. უბრალოდ სვეტთა მნიშვნელობები მიმართვაში იმ თანმიმდევრობით უნდა მივუთითოთ რა თანმიმდევრობითაც ცხრილში გვხვდება სვეტები.INSERT INTO table_name VALUES (value1, value2, value3, ...);კონკრეტული მაგალითიINSERT INTO Customers (CustomerName, ContactName, Address, City, PostalCode, Country)შევნიშნოთ რომ ჩანაწერში არ მიგვითითებია CustomerID ველის მნიშვნელობა, ეს იმიტომ რომ ეს ველი არის auto-increment და მისი მნიშვნელობა ავტომარტურად დაგენერირდება ჩანაწერის შექმნისას (auto-increment-ის შესახებ ვისაუბრებთ მე-10-ე თავში).
VALUES ('Cardinal', 'Tom B. Erichsen', 'Skagen 21', 'Stavanger', '4006', 'Norway'); - 7. მნიშვნელობა NULL
-
ველი მნიშვნელობით NULL იგივეა რაც ველი რომელსაც არ აქვს მითითებული მნიშვნელობა. თუ ცხრილის რომელიმე სვეტის მითითება არააუცილებელია,
მაშინ შესაძლებელია ჩანაწერის განახლებისას ან ჩანაწერის დამატებისას ამ ველის მნიშვნელობა საერთოდ არ მივუთითოთ. ამ შემთხვევაში ველის მნიშვნელობა
იქნება NULL. მნიშვნელოვანია იმის გააზრება, რომ მნიშვნელობა NULL განსხვავდება მნიშვნელობა ნოლისაგან, ან იმ მნიშვნელობისაგან რომელიც შეიცავს
ცარიელ, გამოტოვებულ ადგილებს.
IS NULL და IS NOT NULL ოპერატორები
იმის გასაგებად ველის მნიშვნელობა არის თუ არა NULL უტოლობის ოპერატორებს, როგორებიცაა =, <, ან <>, ვერ გამოვიყენებთ. ამაში დაგვეხმარება IS NULL და IS NOT NULL ოპერატორები.SELECT column_names FROM table_name WHERE column_name IS NULL;SELECT column_names FROM table_name WHERE column_name IS NOT NULL;მაგალითისათვის ცხრილიდან ამოვარჩიოთ (ცხრილი მოყვანილია მე-2-ე თავში) ის ჩანაწერები სადაც არ არის მითითებული მისამართი ანუ Address ველის მნიშვნელობაSELECT LastName, FirstName, Address FROM Persons WHERE Address IS NULL;შესაბამისად, მისამართმითითებული მომხმარებლები ამოირჩევა შემდეგნაირადSELECT LastName, FirstName, Address FROM Persons WHERE Address IS NOT NULL; - 8. UPDATE განაცხადი
-
UPDATE განაცხადი გამოიყენება ცხრილის ჩანაწერთა განახლებისათვის. სინტაქსი ასეთია
UPDATE table_name SET column1 = value1, column2 = value2, ... WHERE condition;ამ განაცხადის გამოყენებისას ყოველთვის უნდა ვიყოთ ფრთხილად, აუცილებლად უნდა მივუთითოთ WHERE წინადადების განმსაზღვრელი პირობა, ანუ განვსაზღვროთ თუ რომელი ჩანაწერის განახლება გვინდა, წინააღმდეგ შემთხვევაში ცხრილის ყველა ჩანაწერი განახლდება. მაგალითისათვის ცხრილში განვაახლოთ ContactName და City სვეტების მნიშვნელობა იმ ჩანაწერისათვის რომლის CustomerID = 1UPDATE Customers SET ContactName = 'Alfred Schmidt', City= 'Frankfurt' WHERE CustomerID = 1;რამდენიმე ჩანაწერის ერთდროულად განახლება
ახლა განვაახლოთ ყველა ის ჩანაწერი სადაც Country='Mexico'UPDATE Customers SET ContactName='Juan' WHERE Country='Mexico'; - 9. DELETE განაცხადი
-
DELETE განაცხადი გამოიყენება ცხრილის ჩანაწერთა წასაშლელად. სინტაქსი ასეთია
DELETE FROM table_name WHERE condition;ამ განაცხადის გამოყენებისას ყოველთვის უნდა ვიყოთ ფრთხილად, აუცილებლად უნდა მივუთითოთ WHERE წინადადების განმსაზღვრელი პირობა, ანუ განვსაზღვროთ თუ რომელი ჩანაწერის წაშლა გვინდა, წინააღმდეგ შემთხვევაში ცხრილის ყველა ჩანაწერი წაიშლება. მაგალითისათვის ცხრილში წავშალოთ ის ჩანაწერის რომელშიც CustomerName ველის მნიშვნელობა არის 'Alfreds Futterkiste'.DELETE FROM Customers WHERE CustomerName='Alfreds Futterkiste';თუ ცხრილის ყველა ჩანაწერის წაშლა გვინდა ვიქცევით ასე ახლა განვაახლოთ ყველა ის ჩანაწერი სადაც Country='Mexico'DELETE FROM table_name;ან ასეDELETE * FROM table_name; - 10. TOP, LIMIT და ROWNUM წინადადებები
-
SELECT TOP წინადადება
SELECT TOP წინადადება გამოიყენება დასაბრუნებელი ჩანაწერების რაოდენობის განსასაზღვრად. ეს წინადადება საქკმაოდ ეფექტურად მუშაობს ცხრილებთად რომლებიც ათასობით ჩანაწერს შეიცავენ რადგან დიდი რაოდენობის ჩანაწერების დაბრუნებამ შეიძლება სისტემის ეფექტურად მუშაობაზე იქონიოს გავლენა. SELECT TOP წინადადებას არ აქვს ყველა მბ-ს სისტემის მხარდაჭერა. მაგალითად MySQL სისტემას ჩანაწერთა ლიმიტირებისათვის აქვს LIMIT წინადადება, Oracle-ში კი ამისათვის გამოიყენება ROWNUM.SQL Server / MS Access სინტაქსი
SELECT TOP number|percent column_name(s) FROM table_name WHERE condition;MySQL სინტაქსი
SELECT column_name(s) FROM table_name WHERE condition LIMIT number;Oracle სინტაქსი
SELECT column_name(s) FROM table_name WHERE ROWNUM <= number;შემდეგი SQL განაცხადი ამოარჩევს პირველ 3 ჩანაწერს "Customers" ცხრილიდანSELECT TOP 3 * FROM Customers;ეს ჩანაწერი ტოლფასია შემდეგი ჩანაწერისაSELECT * FROM Customers LIMIT 3;ახლა იგივე ჩავწეროთ ROWNUM-ის საშუალებითSELECT * FROM Customers WHERE ROWNUM <= 3;TOP PERCENT
შემდეგი SQL ამოარჩევს "Customers" ცხრილის ჩანაწერების პირველ 50%-სSELECT TOP 50 PERCENT * FROM Customers; - 11. MIN() და MAX() ფუნქციები
-
MIN() ფუნქცია აბრუნებს არჩეული ველის ყველაზე დაბალი მნიშვნელობის შემცველ ჩანაწერს.
MAX() ფუნქცია აბრუნებს არჩეული ველის ყველაზე მაღალი მნიშვნელობის შემცველ ჩანაწერს.SELECT MIN(column_name) FROM table_name WHERE condition;SELECT MAX(column_name) FROM table_name WHERE condition;რაც შეეხება იმას თუ როგორ მოვაქციოთ ამ ფუნქციებით დაბრუნებული მნიშვნელობა PHP ცვლადში$sql = "SELECT MIN(age) AS SmallestAge FROM myguests";
$result = mysqli_query($conn,$sql);
$row = mysqli_fetch_assoc($result);
echo $row["SmallestAge"]; - 12. COUNT(), AVG() და SUM() ფუნქციები
-
COUNT() ფუნქცია აბრუნებს იმ ჩანაწერების რაოდენობას რომლებიც აკმაყოფილებენ მითითებულ კრიტერიუმებს.
SELECT COUNT(column_name) FROM table_name WHERE condition;მაგალითად ცხრილში დავთვალოთ იმ ადამიანთა რიცხვი რომელთა ასაკი არის 25 წელი$sql = "SELECT COUNT(age) as ConcretAge FROM myguests WHERE age=25";AVG() ფუნქცია აბრუნებს რიცხვითი ტიპის მნიშვნელობების შემცველი სვეტის მნიშვნელობების საშუალო არითმეტიკულს.
$result = mysqli_query($conn,$sql);
$row = mysqli_fetch_assoc($result);
echo $row["ConcretAge"];SELECT AVG(column_name) FROM table_name WHERE condition;მაგალითად ცხრილში დავთვალოთ ადამიანთა საშუალო ასაკი$sql = "SELECT AVG(age) as AverageAge FROM myguests";SUM() ფუნქცია აბრუნებს რიცხვითი ტიპის მნიშვნელობების შემცველი სვეტის მნიშვნელობების ჯამს.
$result = mysqli_query($conn,$sql);
$row = mysqli_fetch_assoc($result);
echo $row["AverageAge"];SELECT SUM(column_name) FROM table_name WHERE condition;მაგალითად ცხრილში დავთვალოთ ასაკთა ჯამი$sql = "SELECT SUM(age) as SumAge FROM myguests";
$result = mysqli_query($conn,$sql);
$row = mysqli_fetch_assoc($result);
echo $row["SumAge"]; - 13. LIKE ოპერატორი
-
LIKE ოპერატორი გამოიყენება WHERE წინადადებასთან ერთად იმის გასარკვევად თუ სვეტის რომელი მნიშვნელობა შეიცავს კონკრეტულ ნიმუშს. LIKE ოპერატორთან
ერთად გამოიყენება ორი სიმბოლო (wildcards)
- % - პროცენტსის ნიშანი, იმ შემთხვევაში თუ საძიებელ ნიმუშში ერთი ან მეტი სიმბოლოა
- _ - ქვედა ტირე, იმ შემთხვევაში თუ საძიებელ ნიმუშში ერთი სიმბოლოა
SELECT column1, column2, ... FROM table_name WHERE columnN LIKE pattern;LIKE ოპერატორი აღწერა WHERE CustomerName LIKE 'a%' ეძებს მნიშვნელობებს რომლებიც იწყება "a"-ზე WHERE CustomerName LIKE '[bsp]%' ეძებს მნიშვნელობებს რომლებიც იწყება "b"-ზე, "s"-ზე ან "p"-ზე WHERE CustomerName LIKE '![bsp]%' ეძებს მნიშვნელობებს რომლებიც ar იწყება "b"-ზე, "s"-ზე ან "p"-ზე WHERE CustomerName LIKE '[a-c]%' ეძებს მნიშვნელობებს რომლებიც იწყება "a"-ზე, "b"-ზე ან "c"-ზე WHERE CustomerName LIKE '%a' ეძებს მნიშვნელობებს რომლებიც მთავრდება "a"-ზე WHERE CustomerName LIKE '%or%' ეძებს მნიშვნელობებს რომლებიც შეიცავენ "or" -ს WHERE CustomerName LIKE '_r%' ეძებს მნიშვნელობებს რომლებიც იწყებიან რაიმე სიმბოლოთი და პირველი სიმბოლოს შემდეგ გვხვდება "r" WHERE CustomerName LIKE 'a_%_%' ეძებს მნიშვნელობებს რომლებიც იწყება "a"-ზე და შეიცავენ მინიმუმ 3 სიმბოლოს WHERE ContactName LIKE 'a%o' ეძებს მნიშვნელობებს რომლებიც იწყება "a"-ზე მთავრდება ""o""-ზე - 14. IN ოპერატორი
-
IN ოპერატორი საშუალებას გვაძლევს მივუთითოთ რამოდენიმე მნიშვნელობა WHERE წინადადებაში. ეს ოპერატორი ფაქტიურად არის OR ოპერატორის კომბინაციების
შემოკლებული ვარიანტი, სინტაქსი ასეთია
SELECT column_name(s) FROM table_name WHERE column_name IN (value1, value2, ...);ანSELECT column_name(s) FROM table_name WHERE column_name IN (SELECT STATEMENT);შემდეგი მაგალითი ამოარჩევს ყველა მომხმარებელს რომლებიც არიან შემდეგი ქვეყნებიდან "Germany", "France" ან "UK":SELECT * FROM Customers WHERE Country IN ('Germany', 'France', 'UK');ახლა ვიპოვოთ ის მომხმარებლები, რომლებიც არ არიან ამ ქვეყნებიდანSELECT * FROM Customers WHERE Country NOT IN ('Germany', 'France', 'UK');ვთქვათ "Customers" ცხრილის გარდა გვაქვს მეორე ცხრილი სადაც ქალაქებია მითითებული - "Cities". შემდეგი მაგალითი ყველა იმ მომხმარებელს ამოარჩევს, რომლებიც "Cities" ცხრილში შეყვანილი ქალაქებიდან არიანSELECT * FROM Customers WHERE city IN (SELECT city FROM cities); - 15. BETWEEN ოპერატორი
-
BETWEEN ოპერატორი ირჩევს შედეგს რომელიც მითითებულ დიაპაზონშია, მნიშვნელობები შეიძლება იყოს რიცხვები, ტექსტები ან თარიღი. ოპერატორი თავის თავში
მოიცავს საწყის და ბოლო მნიშვნელობებს. სინტაქსი ასეთია
SELECT column_name(s) FROM table_name WHERE column_name BETWEEN value1 AND value2;შემდეგი მაგალითი აარჩევს მომხმარებლებს, რომელთა ასაკი 20-დან 30 წლამდეაSELECT * FROM Customers WHERE age BETWEEN 20 AND 30;NOT BETWEEN ოპერატორი
ახლა კი ავარჩიოთ ის მომხმარებლები რომელთა ასაკიც 10-20 დიაპაზონში არ არისSELECT * FROM Customers WHERE age NOT BETWEEN 20 AND 30;BETWEEN და IN ოპერატორები ერთად
შემდეგი მაგალითი აარჩევს პროდუქტს რომელთა ფასები 10-20 დიაპაზონშია და რომლებიც არ წკუთვნია 1, 2 და 3 CategoryID მქონე კატეგორიებსSELECT * FROM Products WHERE (Price BETWEEN 10 AND 20) AND NOT CategoryID IN (1,2,3);ტექსტური მნიშვნელობები
SELECT * FROM Products WHERE ProductName BETWEEN 'Carnarvon Tigers' AND 'Mozzarella di Giovanni';თარიღის ტიპის მნიშვნელობები
ავარჩიოთ შეკვეთები რომელთა თარიღები არის '04-July-1996' და '09-July-1996' შუალედშიSELECT * FROM Orders WHERE OrderDate BETWEEN #07/04/1996# AND #07/09/1996#; - 16. ფსევდონიმები (Aliases)
-
SQL ფსევდონიმები გამოიყენება სვეტის ან ცხრილის დროებითი სახელის განსასაზღვრავად. სვეტის ფსევდონიმის განსაზღვრა ხდება ასე
SELECT column_name AS alias_name FROM table_name;ცხრილისა კი ასეSELECT column_name(s) FROM table_name AS alias_name;ფსევდონიმები გამოიყენება იმისათვის რათა სვეტთა დასახელებები გახდეს უფრო წაკითხვადი, მაგალითად სიტყვა "ID" უფრო ადვილი ჩასაწერი და წასაკითხია ვიდრე სიტყვა "CustomerID", იგივე შეიძლება ითქვას სიტყვების შემდეგ წყვილზე: "Customer"-"CustomerName". ასე რომ ჩავანაცვლოთ რთული უფრო მარტივითSELECT CustomerID as ID, CustomerName AS Customer FROM Customers;ფსეევდონიმი არსებობს მანამ, სანამ არსებობს SQL განაცხადი. თუ ფსევდონიმი შეიცავს გამოტოვებულ ადგილებს მაშინ ის უნდა მოთავსდეს ფიგურულ ფრჩხილებშიSELECT CustomerName AS Customer, ContactName AS [Contact Person] FROM Customers;ცხრილის ფსევდონიმები
მოყვანილი მაგალითი ამოარჩევს იმ მომხმარებლის შეკვეთებს რომლის CustomerID=4 (Around the Horn). ვიყენებთ Customers" და "Orders" ცხრილებს ხოლო მათი ფსევდინიმებია "c" და "o"SELECT o.OrderID, o.OrderDate, c.CustomerNameფსევდონიმების გარეშე ეს განაცხადი მიიღებდა გაცილებით უფრო გრძელ სახეს
FROM Customers AS c, Orders AS o
WHERE c.CustomerName="Around the Horn" AND c.CustomerID=o.CustomerID;SELECT Orders.OrderID, Orders.OrderDate, Customers.CustomerName
FROM Customers, Orders
WHERE Customers.CustomerName="Around the Horn" AND Customers.CustomerID=Orders.CustomerID; - 17. JOIN წინადადება
-
JOIN წინადადება გამოიყენება ორი ან მეტი ისეთი ცხრილის სტრიქონების გასაერთიანებლად, რომლებსაც აქვთ საერთო, გადაკვეთის წერტილი, საერთო სვეტი.
მაგალითად ცხრილი "Orders"
და ცხრილი "Customers"OrderID CustomerID OrderDate 10308 2 1996-09-18 10309 37 1996-09-19 10310 77 1996-09-20
მათ აქვთ საერთო სვეტი "CustomerID". ამ ორი ცხრილის ურთიერთდამოკიდებულება და კავშირი განისაზღვრება სწორედ ამ სვეტით. ახლა ჩავწეროთ SQL განაცხადი რომელიც ორივე ცხრილიდან ამოარჩევს იმ ჩანაწერებს რომლებშიც "CustomerID" ველის მნიშვნელობა ერთნაირიაCustomerID CustomerName ContactName Country 1 Alfreds Futterkiste Maria Anders Germany 2 Ana Trujillo Emparedados y helados Ana Trujillo Mexico 3 Antonio Moreno Taquería Antonio Moreno Mexico SELECT Orders.OrderID, Customers.CustomerName, Orders.OrderDate"CustomerID" ველის საერთო მნიშვნელობა ცხრილში არის CustomerID=2, ასე რომ ამ განაცხადის შედეგი იქნება
FROM Orders
INNER JOIN Customers ON Orders.CustomerID=Customers.CustomerID;OrderID CustomerName OrderDate 10308 Ana Trujillo Emparedados y helados 1996-09-18 JOIN წინადადების სახეები
- (INNER) JOIN: აბრუნებს ჩანაწერებს რომელთაც აქვთ საერთო მნიშვნელობები ორივე ცხრილში
- LEFT (OUTER) JOIN: აბრუნებს მარცხენა ცხრილის ყველა ჩანაწერს და მარჯვენა ცხრილის მხოლოდ იმ ჩანაწერებს რომლებიც შეიცავენ მარცხენა ცხრილის მნიშვნელობათა ტოლფას მნიშვნელობებს.
- RIGHT (OUTER) JOIN: აბრუნებს მარჯვენა ცხრილის ყველა ჩანაწერს და მარცხენა ცხრილის მხოლოდ იმ ჩანაწერებს რომლებიც შეიცავენ მარჯვენა ცხრილის მნიშვნელობათა ტოლფას მნიშვნელობებს.
- FULL (OUTER) JOIN: აბრუნებს ისეთ ჩანაწერებს რომელიც მოიცავს დამთხვევებს მარცხენა არ მარჯვენა ცხრილიდან
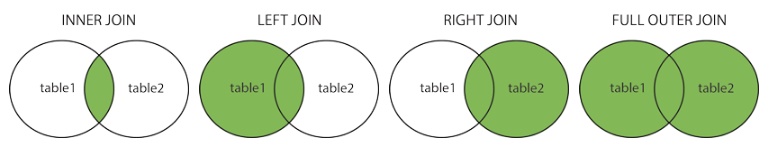
INNER JOIN
სიტყვა-გასაღები INNER JOIN აბრუნებს ჩანაწერებს რომელთაც აქვთ საერთო მნიშვნელობები ორივე ცხრილშიSELECT column_name(s)კონკრეტული მაგალითი
FROM table1
INNER JOIN table2 ON table1.column_name = table2.column_name;1. SELECT Orders.OrderID, Customers.CustomerName, Orders.OrderDateამ განაცხადის შედეგი ზემოთ უკვე ვნახეთ მაგრამ ახლა განაცხადის სინტაქსი ავხსნათ სიტყვა-სიტყვით: როგორც უკვე ვთქვით, JOIN ოპერატორის მიზანი ცხრილთა გაერთიანებაა კონკრეტული წესების მიხედვით (ინგლ: Join - შეერთება, გაერთიანება, დაკავშირება), ცხრილთა გაერთიანებით, ბუნებრივია, მიიღება ისევ ცხრილი, ცხრილი კი უნდა შეიცავდეს გარკვეულ სვეტებს, განაცხადის პირველი ხაზი განსაზღვრავს სწორედ ამ სვეტთა დასახელებებს და აგრეთვე იმას თუ რომელი სვეტი რომელი ცხრილიდან უნდა ამოირჩეს. "FROM Orders INNER JOIN" ჩანაწერი განსაზღვრავს იმ ცხრილებს რომლებიც უნდა გაერთიანდნენ და აგრეთვე გაერთიანების ტიპს (ამ შემთხვევაში INNER). "ON Orders.CustomerID=Customers.CustomerID;" ჩანაერი კი განსაზღვრავს გაერთიანების კრიტერიუმს,
2. FROM Orders
3. INNER JOIN Customers ON Orders.CustomerID=Customers.CustomerID;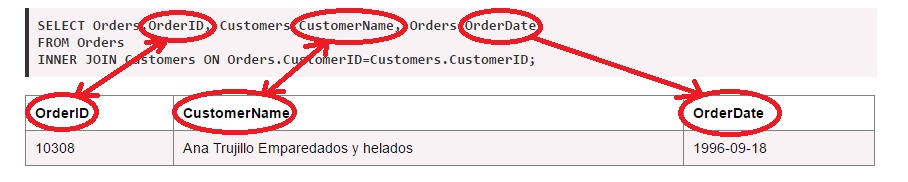
LEFT JOIN
სიტყვა-გასაღები LEFT JOIN არჩევს ყველა ჩანაწერს მარცხენა ცხრილიდან (table1) და მხოლოდ საერთო მნიშვნელობის მქონე ჩანაწერებს მარჯვენა ცხრილიდან (table2). მარჯვენა ცხრილის არასაერთო მნიშვნელობები კი ხდება NULLSELECT column_name(s)ჩვენი ცხრილის მაგალითზე
FROM table1
LEFT JOIN table2 ON table1.column_name = table2.column_name;SELECT Customers.CustomerName, Orders.OrderIDშედეგი იქნება
FROM Customers
LEFT JOIN Orders ON Customers.CustomerID = Orders.CustomerID;
CustomerName OrderID Ana Trujillo Emparedados y helados 10308 Alfreds Futterkiste NULL Antonio Moreno Taquería NULL RIGHT JOIN
სიტყვა-გასაღები RIGHT JOIN არჩევს ყველა ჩანაწერს მარჯვენა ცხრილიდან (table2) და მხოლოდ საერთო მნიშვნელობის მქონე ჩანაწერებს მარცხენა ცხრილიდან (table1). მარცხენა ცხრილის არასაერთო მნიშვნელობები კი ხდება NULLSELECT column_name(s)ჩვენი ცხრილის მაგალითზე
FROM table1
RIGHT JOIN table2 ON table1.column_name = table2.column_name;SELECT Customers.CustomerName, Orders.OrderIDშედეგი იქნება
FROM Customers
RIGHT JOIN Orders ON Customers.CustomerID = Orders.CustomerID;
CustomerName OrderID Ana Trujillo Emparedados y helados 10308 NULL 10309 NULL 10310 - 18. UNION ოპერატორი
-
UNION ოპერატორი გამოიყენება ორი ან მეტი SELECT განაცხადის შედეგად მიღებული ჩანაწერების გასაერთიანებლად (ინგლ: Union - კავშირი, შეერთება, გაერთიანება).
- UNION ოპერატორით გაერთიანებული ყველა SELECT განაცხადი უნდა მოიცავდეს სვეტების ერთნაირ რაოდენობას.
- სვეტები უნდა მოიცავდნენ ერთი და იგივე ტიპის მონაცემებს.
- სვეტები უნდა იყვნენ ერთი და იგივე თანმიმდევრობით მითითებულნი ყველა SELECT განაცხადში.
SELECT column_name(s) FROM table1UNION ოპერატორი კრებს მხოლოდ განსხვავებულ მნიშვნელობებს, იმისათვის რათა გაერთიანებაში შევიდეს ველების ერთნაირი მნიშვნელობები უნდა გამოვიყენოთ UNION ALL ოპერატორი
UNION
SELECT column_name(s) FROM table2;SELECT column_name(s) FROM table1დავუშვათ გვაქვს ორი ცხრილი რომლებშიც, ორივე მათგანში გვხვდება სვეტი "City", გავაერთიანოთ ეს ქალაქები ერთ ახალ ცხრილში
UNION ALL
SELECT column_name(s) FROM table2;SELECT City FROM Customers
UNION
SELECT City FROM Suppliers
ORDER BY City; - 19. GROUP BY ოპერატორი
-
GROUP BY ოპერატორი ხშირად გამოიყენება აგრეგატულ ფუნქციებთან (ინგლ: Aggregate - დაჯგუფება; გაერთიანება). COUNT, MAX, MIN, SUM და AVG აგრეგატული ფუნქციები გამოთვლებს ატარებენ მონაცემთა ნაკრებზე, შედეგად კი აბრუნებენ ერთ მონაცემს, GROUP BY ოპერატორის დანიშნულებაა საპასუხო ნაკრების ერთი ან მეტი სვეტის მიხედვით დაჯგუფება.
SELECT column_name(s)მაგალითად გვაქვს ცხრილი "employee" რომელიც შეიცავს ინფორმაციას თანამშრომლებთა შესახებ
FROM table_name
WHERE condition
GROUP BY column_name(s)
ORDER BY column_name(s);
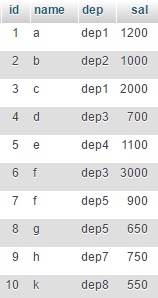
და გვსურს გავიგოთ რომელ დეპარტამენტში რამდენია მაქსიმალური ხელფასიSELECT dep, MAX(sal) FROM employee GROUP BY dep;შედეგი იქნება

იგივე ჩანაწერი შევქმნათ ალიასის ანუ ფსევდონიმის დახმარებითSELECT dep, MAX(sal) AS MaxSalary FROM employee GROUP BY dep;შედეგი იქნება

დაწვრილებით განვიხილოთ GROUP BY ოპერატორის მუშაობის პრინციპი. როგორც აღვნიშნეთ, ოპერატორი მუშაობს აგრეგატულ ფუნქციებთან და მისი ჩაწერის სინტაქსი შეიცავს ორ აუცილებელ კომპონენტს:- აგრეგატული ფუნქციის განსაზღვრა (COUNT, MAX, MIN, SUM, AVG).
- დაჯგუფება (GROUP BY).

პირველი კომპონენტი ანუ აგრეგატული ფუნქცია კი ატარებს შესაბამის გამოთვლებს: საშუალო, მინიმალური, მაქსიმალური ხელფასი თითოეული ჯგუფისათვის, ან შესაძლებელია COUNT აგრეგატული ფუნქციით დაითვალოს თუ რამდენი სხვადასხვანაირი ხელფასია თითოეულ დეპარტამენტში.GROUP BY და JOIN
ვთქვათ გვაქვს ორი ცხრილი, შეკვეთების ცხრილი - "orders" და მიმწოდებლების ცხრილი "shippers".
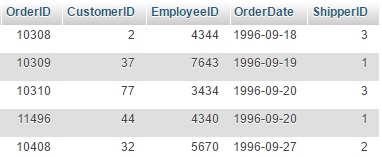
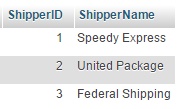
და გვსურს მივიღოთ ცხრილი რომელსაც ექნება შემდეგი ველები: მიმწოდებლის ID (ShipperID), მიმწოდებლის დასახელება (ShipperName) და მიტანილი შეკვეთების რაოდენობა (OrderNum).
როგორც ვხედავთ პირველ ცხრილში თითოეულ შეკვეთას მითითებული აქვს მიმწოდებლის id (ShipperID), დავაჯგუფოთ შეკვეთები ShipperID ველის მიხედვით და დავთვალოთ თუ რამდენი შეკვეთაა თითოეულ ჯგუფში ანუ რამდენი შეკვეთა შეესაბამება თითოეულ ShipperID-ს.SELECT ShipperID, COUNT(OrderID) FROM orders GROUP BY ShipperID;ამ ჩანაწერის შედეგი იქნება
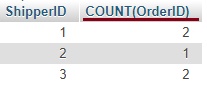
როგორც ვხედავთ მეორე ველის ანუ შეკვეთების რაოდენობების ველის დასახელება არც თუ ისე სასიამოვნოდ გამოიყურება. დავიხმაროთ ალიასი და გამოვასწოროთ ეს ხარვეზიSELECT ShipperID, COUNT(OrderID) AS OrderNum FROM orders GROUP BY ShipperID;ამ ჩანაწერის შედეგი იქნება
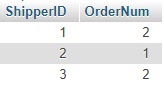
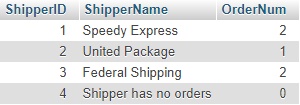
მიზნისაგან ისღა გვაშორებს, რომ ამ ცხრილში ჩავამატოთ მიმწოდებლის დასახელების ველი ShipperName, ამისათვის უნდა გავაერთიანოთ მიმწოდებლების ცხრილი "shippers" და ჩვენს მიერ, GROUP BY ოპერატორის მეშვეობით მიღებული ცხრილი, ამაში დაგვეხმარება LEFT JOIN ოპერატორიSELECT shippers.ShipperID, shippers.ShipperName, B.OrderNum FROM shippers LEFT JOIN (SELECT ShipperID, COUNT(OrderID) AS OrderNum FROM orders GROUP BY ShipperID) AS B ON shippers.ShipperID=B.ShipperID;
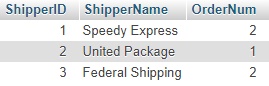
მაგრამ აქ ყურადღება უნდა მიექცეს შემდეგ მომენტს: შეიძლება მოხდეს ისე, რომ მიმწოდებლების ცხრილში შეტანილი იყოს ისეთი მიმწოდებელი, რომელსაც არცერთი შეკვეთა არ მიუტანია, ასეთ შემთხვევაში ჩვენს მიერ ბოლოს განსაზღვრული მოთხოვნა დააბრუნებს შემდეგ შედეგს
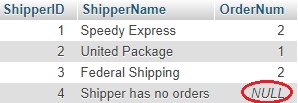
ჩავანაცვლოთ NULL მნიშვნელობები ნოლით, ამაში დაგვეხმარება IFNULL ოპერატორიSELECT shippers.ShipperID, shippers.ShipperName, IFNULL(B.OrderNum,0) AS OrderNum FROM shippers LEFT JOIN (SELECT ShipperID, COUNT(OrderID) AS OrderNum FROM orders GROUP BY ShipperID) AS B ON shippers.ShipperID=B.ShipperID;